El aumento del 13% en el interés por el fitness en abril da inicio a la sesión de entrenamiento de la IA en tus datos.
En promedio, cada enero se observa un aumento del 23 % en el interés por las búsquedas relacionadas con el fitness, y abril trae consigo un segundo incremento del 13 % a medida que la gente se prepara para el verano. Sin embargo, un nuevo estudio revela que el auge del fitness digital conlleva un coste oculto: las aplicaciones populares recopilan datos vinculados a tu identidad y entrenan su IA. Strava, por ejemplo, recopila 20 tipos de datos vinculados a tu identidad y utiliza la información para entrenar sus modelos de IA y aprendizaje automático. En cambio, otras empresas como Peloton, que recopilan 2 tipos de datos vinculados a tu identidad, afirman que cualquier dato personal procesado por la IA se utiliza exclusivamente para mejorar sus servicios.
No sorprende que la IA se esté incorporando al mundo del fitness y aplicaciones similares. Sin embargo, entrenar la IA con datos personales sin un consentimiento explícito e informado no es innovación, sino una invasión de la privacidad y la confianza. Estas prácticas hacen que las personas cedan sus datos sin saberlo al usar funciones de IA, sin comprender claramente cómo se procesan sus datos, afirma Luis Costa, jefe de investigación de Surfshark.
Google Trends revela un patrón claro.
Un estudio de la empresa de ciberseguridad Surfshark revela que las búsquedas de los términos “fitness” y “entrenamiento personal” se disparan a nivel mundial en invierno y experimentan un notable aumento en primavera, a partir de abril. Desde 2022, el interés de búsqueda por “fitness” alcanzó su valor máximo (100) en enero de 2026. El interés por “entrenamiento personal” también ha sido notable, llegando a un máximo de 100 en el invierno de 2026, frente a los 37 de enero de 2025, lo que supone un impresionante aumento de 2,7 veces.
En abril se observa una segunda oleada de interés por el “fitness”, con un crecimiento promedio de aproximadamente el 13%. Las tendencias para el “entrenamiento personal” son similares, con un crecimiento que comienza en abril y alcanza su punto máximo en agosto, con 75 de cada 100.
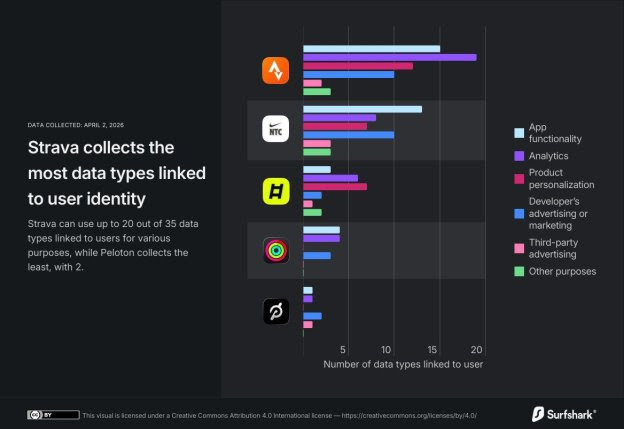
Strava recopila 20 tipos de datos, Nike Training Club – 19 tipos de datos vinculados a tu identidad.
La IA está transformando el mundo del fitness al personalizar los entrenamientos mediante los datos del usuario. Estos datos, además de mejorar la experiencia individual de entrenamiento, también pueden utilizarse para el entrenamiento con IA.
Por ejemplo, Strava utiliza la información recopilada de los usuarios para mejorar la calidad, la fiabilidad y/o la precisión de sus funciones de IA mediante la creación, el desarrollo, el entrenamiento, las pruebas, la mejora y el mantenimiento de modelos de IA y aprendizaje automático gestionados por Strava o sus proveedores de servicios. Sin embargo, afirman que, siempre que sea posible, utilizan información agregada y anonimizada para las funciones de IA. Por otro lado, Peloton utiliza los datos recopilados para crear, entrenar, analizar y mejorar la precisión de sus servicios, optimizar sus productos y aumentar la eficiencia operativa. Si bien Peloton puede utilizar proveedores de servicios de IA externos, declaran explícitamente que cualquier dato personal procesado por estas tecnologías se utiliza exclusivamente para mejorar sus servicios.
Entre las aplicaciones de entrenamiento analizadas, Strava es la que recopila más datos vinculados a la identidad del usuario, reuniendo 20 de los 35 tipos de datos disponibles en la App Store de Apple. Estos tipos de datos incluyen la ubicación, el historial de compras y búsquedas, fotos y videos, y otro contenido del usuario. Nike Training Club recopila 19 tipos de datos, mientras que Peloton solo recopila 2.
Si bien muchos de estos tipos de datos pueden ser esenciales para el funcionamiento de la aplicación, también pueden utilizarse para fines como publicidad, análisis, personalización de productos y más. Por ejemplo, Ladder utiliza solo 3 de los 10 tipos de datos vinculados a los usuarios para el funcionamiento de la aplicación, pero recopila 7 tipos de datos para la personalización de productos y emplea 6 para análisis. Las empresas también pueden acceder y utilizar datos biométricos confidenciales adicionales cuando estas aplicaciones se conectan a dispositivos portátiles o servicios de terceros.
“La IA aplicada al fitness está introduciendo un nuevo método para la recopilación exhaustiva de información, lo que permite la creación de perfiles detallados de los usuarios. Esto suscita preocupación por la privacidad de la información personal sensible, que a menudo nunca se comparte ni siquiera con amigos, ya que se analiza y se utiliza para entrenar modelos de IA. La gente suele pasar por alto los riesgos de seguridad, creyendo que la IA es una entidad impersonal. Sin embargo, esta información puede quedar expuesta en filtraciones y, en última instancia, ser explotada por las grandes tecnológicas o incluso por actores malintencionados”, afirma Costa.
Además, cuatro de las cinco aplicaciones analizadas también utilizan datos para el seguimiento, según lo indicado por los desarrolladores en la información proporcionada en la App Store de Apple, siendo Apple Fitness+ la excepción. El “seguimiento” se refiere a la vinculación de los datos del usuario o del dispositivo recopilados por la aplicación (como el ID de usuario, el ID del dispositivo o el perfil) con datos del usuario o del dispositivo recopilados de otras aplicaciones, sitios web o plataformas fuera de línea con fines publicitarios personalizados. El seguimiento también incluye compartir datos del usuario o del dispositivo con intermediarios de datos.




